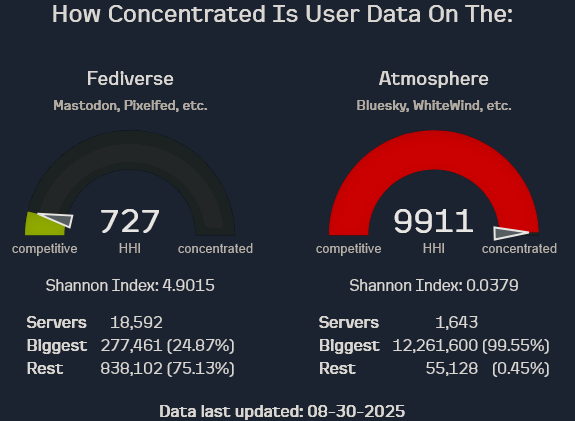
Doing it this way is why small instances gets hammered when a user’s post goes viral.
And as for moderation bluesky also carries information with the top post from the post author and allows hiding replies too, etc. This gets enforced on the appview side, so the posting user’s PDS is unscathed if it goes viral.
Bluesky is built to assume a handful of big relay (remember that a relay can merge in contents of another) and a bunch of appview and a ton of PDS servers, feed generators, moderation labelers, etc.
Realistically, the relay network will likely end up voluntarily adopting a tree topology - hobbyist communities would run small relays bundling all activity from members’ PDS servers, then a larger relay in front gathers everything from a ton of smaller relays and makes it available to appviews
Doing it this way is why small instances gets hammered when a user’s post goes viral.
Setting up caching in the reverse proxy layer would alleviate this a lot of this. Like, GoToSocial only recommends to set up caching for the key and webfinger endpoints, where having it set up to cache posts and profiles for like 60 seconds (or however long the Cache-Control header says, Mastodon defaults to 180s) would alleviate the strain on the server so much.
There are other thing you can do, like this post explains some other things for Misskey, but the defaults should be sensible so you don’t have to be a sysadmin expert to host an instance and they’re currently not. I host 2 Lemmy instances (ukfli.uk and sappho.social) from a £5/month VPS and they’re able to handle bursts of hundreds of requests without issue.
Bluesky is built to assume a handful of big relay (remember that a relay can merge in contents of another) and a bunch of appview and a ton of PDS servers, feed generators, moderation labelers, etc.
People are already building small, non-archival relays so this assumption seems mute. It’s also important to remember that relays are an optimisation, not a core part of the protocol.

{kind=link}
Doing it this way is why small instances gets hammered when a user’s post goes viral.
And as for moderation bluesky also carries information with the top post from the post author and allows hiding replies too, etc. This gets enforced on the appview side, so the posting user’s PDS is unscathed if it goes viral.
Bluesky is built to assume a handful of big relay (remember that a relay can merge in contents of another) and a bunch of appview and a ton of PDS servers, feed generators, moderation labelers, etc.
Realistically, the relay network will likely end up voluntarily adopting a tree topology - hobbyist communities would run small relays bundling all activity from members’ PDS servers, then a larger relay in front gathers everything from a ton of smaller relays and makes it available to appviews
Setting up caching in the reverse proxy layer would alleviate this a lot of this. Like, GoToSocial only recommends to set up caching for the key and webfinger endpoints, where having it set up to cache posts and profiles for like 60 seconds (or however long the
Cache-Controlheader says, Mastodon defaults to 180s) would alleviate the strain on the server so much.There are other thing you can do, like this post explains some other things for Misskey, but the defaults should be sensible so you don’t have to be a sysadmin expert to host an instance and they’re currently not. I host 2 Lemmy instances (ukfli.uk and sappho.social) from a £5/month VPS and they’re able to handle bursts of hundreds of requests without issue.
People are already building small, non-archival relays so this assumption seems mute. It’s also important to remember that relays are an optimisation, not a core part of the protocol.